В оглавление Основы информационных технологий в профессиональной деятельности
Тематические коллекции ссылок
Тематические коллекции ссылок - это списки, составленные группой профессионалов или даже коллекционерами-одиночками. Очень часто узкоспециализированная тема может быть раскрыта одним специалистом лучше, чем группой сотрудников крупного каталога. Тематических коллекций в Сети так много, что давать конкретные адреса не имеет смысла.
Подбор доменного имени
Каталог - удобная система поиска, однако для того, чтобы попасть на сервер компании Microsoft или IBM, вряд ли имеет смысл обращаться к каталогу. Угадать название соответствующего сайта нетрудно: www.microsoft.com, www.ibm.com или www.microsoft.ru, www.ibm.ru - сайты российских представительств этих компаний.
Аналогично, если пользователю необходим сайт, посвященный погоде в мире, его логично искать на сервере www.weather.com. В большинстве случаев поиск сайта с ключевым словом в названии эффективнее, чем поиск документа, в тексте которого это слово используется. Если западная коммерческая компания (или проект) имеет односложное название и реализует в Сети свой сервер, то его имя с высокой вероятностью укладывается в формат www.name.com, а для Рунета (российской части Сети) - www.name.ru, где name - имя компании или проекта. Подбор адреса может успешно конкурировать с другими приемами поиска, поскольку при подобной системе поиска можно установить соединение с сервером, который не зарегистрирован ни в одной поисковой системе. Однако, если подобрать искомое имя не удается, придется обратиться к поисковой машине.
Поисковые машины
Скажи мне, что ты ищешь в Интернете, и я скажу, кто ты
Если бы компьютер был высокоинтеллектуальной системой, которой можно было легко объяснить, что вы ищете, то он выдавал бы два-три документа - именно те, которые вам нужны. Но, к сожалению, это не так, и в ответ на запрос пользователь обычно получает длинный список документов, многие из которых не имеют никакого отношения к тому, о чем он спрашивал. Такие документы называются нерелевантными (от англ. relevant - подходящий, относящийся к делу). Таким образом, релевантный документ - это документ, содержащий искомую информацию. Очевидно, что от умения грамотно выдавать запрос зависит процент получаемых релевантных документов. Доля релевантных документов в списке всех найденных поисковой машиной документов называется точностью поиска. Нерелевантные документы называют шумовыми. Если все найденные документы релевантные (шумовых нет), то точность поиска составляет 100%. Если найдены все релевантные документы, то полнота поиска - 100%.
Таким образом, качество поиска определяется двумя взаимозависимыми параметрами: точностью и полнотой поиска. Увеличение полноты поиска снижает точность, и наоборот.
Как работает поисковая машина
Поисковые системы можно сравнить со справочной службой, агенты которой обходят предприятия, собирая информацию в базу данных (рис. 4.21). При обращении в службу информация выдается из этой базы. Данные в базе устаревают, поэтому агенты их периодически обновляют. Некоторые предприятия сами присылают данные о себе, и к ним агентам приезжать не приходится. Иными словами, справочная служба имеет две функции: создание и постоянное обновление данных в базе и поиск информации в базе по запросу клиента.

Рис. 4.21. Поисковые системы можно сравнить со справочной службой, агенты которой обходят предприятия, собирая информацию в базу данных
Аналогично, поисковая машина состоит из двух частей: так называемого робота (или паука), который обходит серверы Сети и формирует базу данных поискового механизма.
База робота в основном формируется им самим (робот сам находит ссылки на новые ресурсы) и в гораздо меньшей степени - владельцами ресурсов, которые регистрируют свои сайты в поисковой машине. Помимо робота (сетевого агента, паука, червяка), формирующего базу данных, существует программа, определяющая рейтинг найденных ссылок.
Принцип работы поисковой машины сводится к тому, что она опрашивает свой внутренний каталог (базу данных) по ключевым словам, которые пользователь указывает в поле запроса, и выдает список ссылок, ранжированный по релевантности.
Следует отметить, что, отрабатывая конкретный запрос пользователя, поисковая система оперирует именно внутренними ресурсами (а не пускается в путешествие по Сети, как часто полагают неискушенные пользователи), а внутренние ресурсы, естественно, ограниченны. Несмотря на то что база данных поисковой машины постоянно обновляется, поисковая машина не может проиндексировать все Web-документы: их число слишком велико. Поэтому всегда существует вероятность, что искомый ресурс просто неизвестен конкретной поисковой системе.
Эту мысль наглядно иллюстрирует рис. 4.22. Эллипс 1 ограничивает множество всех Web-документов, существующих на некоторый момент времени, эллипс 2 - все документы, которые проиндексированы данной поисковой машиной, а эллипс 3 - искомые документы. Таким образом, найти с помощью данной поисковой машины можно лишь ту часть искомых документов, которые ею проиндексированы.
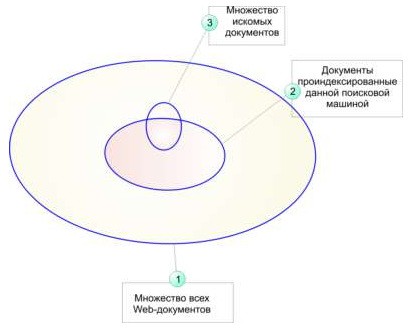
Рис. 4.22. Схема, поясняющая возможности поиска
Проблема недостаточности полноты поиска состоит не только в ограниченности внутренних ресурсов поисковика, но и в том, что скорость робота ограниченна, а количество новых Web-документов постоянно растет. Увеличение внутренних ресурсов поисковой машины не может полностью решить проблему, поскольку скорость обхода ресурсов роботом конечна.
При этом считать, что поисковая машина содержит копию исходных ресурсов Интернета, было бы неправильно. Полная информация (исходные документы) хранится отнюдь не всегда, чаще хранится лишь ее часть - так называемый индексированный список, или индекс, который гораздо компактнее текста документов и позволяет быстрее отвечать на поисковые запросы.
Для построения индекса исходные данные преобразуются так, чтобы объем базы был минимальным, а поиск осуществлялся очень быстро и давал максимум полезной информации. Объясняя, что такое индексированный список, можно провести параллель с его бумажным аналогом - так называемым конкордансом, т.е. словарем, в котором в алфавитном порядке перечислены слова, употребляемые конкретным писателем, а также указаны ссылки на них и частота их употребления в его произведениях.
Очевидно, что конкорданс (словарь) гораздо компактнее исходных текстов произведений и найти в нем нужное слово намного проще, нежели перелистывать книгу в надежде наткнуться на нужное слово.
Построение индекса
Схема построения индекса показана на рис. 4.23. Сетевые агенты, или роботы-пауки, "ползают" по Сети, анализируют содержимое Web-страниц и собирают информацию о том, что и на какой странице было обнаружено.
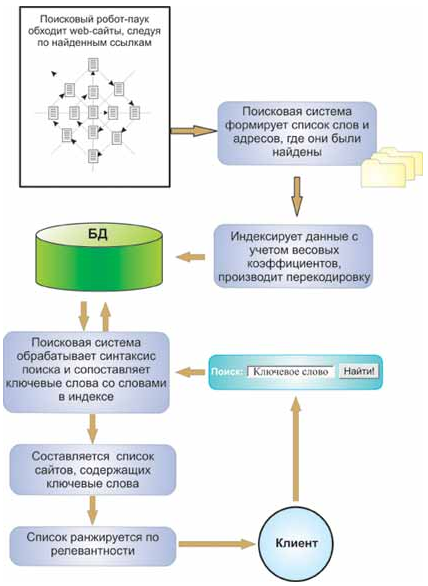
Рис. 4.23. Роботы-пауки просматривают информационное наполнение Web-страниц и создают базу, на основе которой производится поиск
При нахождении очередной HTML-страницы большинство поисковых систем фиксируют слова, картинки, ссылки и другие элементы (в разных поисковых системах по-разному), содержащиеся на ней. Причем при отслеживании слов на странице фиксируется не только их наличие, но и местоположение, т.е. где эти слова находятся: в заголовке (title), подзаголовках (subtitles), в метатэгах (meta tags) или в других местах. При этом обычно фиксируются значимые слова, а союзы и междометия типа "а", "но" и "или" игнорируются. Метатэги позволяют владельцам страниц определить ключевые слова и тематику, по которым индексируется страница. Это может быть актуально в случае, когда ключевые слова имеют несколько значений. Метатэги могут сориентировать поисковую систему при выборе из нескольких значений слова на единственно правильное. Однако метатэги работают надежно только в том случае, когда заполняются честными владельцами сайта. Недобросовестные владельцы Web-сайтов помещают в свои метатэги наиболее популярные в Сети слова, не имеющие ничего общего с темой сайта. В результате посетители попадают на незапрашиваемые сайты, повышая тем самым их рейтинг. Именно поэтому многие современные поисковики либо игнорируют метатэги, либо считают их дополнительными по отношению к тексту страницы. Каждый робот поддерживает свой список ресурсов, наказанных за недобросовестную рекламу.
Очевидно, что если вы ищете сайты по ключевому слову "собака", то поисковый механизм должен найти не просто все страницы, где упоминается слово "собака", а те, где это слово имеет отношение к теме сайта. Для того чтобы определить, в какой степени то или иное слово имеет отношение к профилю некоторой Web-страницы, необходимо оценить, насколько часто оно встречается на странице, есть ли по данному слову ссылки на другие страницы или нет. Короче говоря, необходимо ранжировать найденные на странице слова по степени важности. Словам присваиваются весовые коэффициенты в зависимости от того, сколько раз и где они встречаются (в заголовке страницы, в начале или в конце страницы, в ссылке, в метатэге и т.п.). Каждый поисковый механизм имеет свой алгоритм присваивания весовых коэффициентов - это одна из причин, по которой поисковые машины по одному и тому же ключевому слову выдают различные списки ресурсов. Поскольку страницы постоянно обновляются, процесс индексирования должен выполняться постоянно. Роботы-пауки путешествуют по ссылкам и формируют файл, содержащий индекс, который может быть довольно большим. Для уменьшения его размеров прибегают к минимизации объема информации и сжатию файла. Имея несколько роботов, поисковая система может обрабатывать сотни страниц в секунду. Сегодня мощные поисковые машины хранят сотни миллионов страниц и получают десятки миллионов запросов ежедневно.
При построении индекса решается также задача снижения количества дубликатов - задача нетривиальная, учитывая, что для корректного сравнения нужно сначала определить кодировку документа. Еще более сложной задачей является отделение очень похожих документов (их называют "почти дубликаты"), например таких, в которых отличается лишь заголовок, а текст дублируется. Подобных документов в Сети очень много - например, кто-то списал реферат и опубликовал его на сайте за своей подписью. Современные поисковые системы позволяют решать подобные проблемы.